Automatic depth map generation, stereo matching, multi-view stereo, Structure from Motion (SfM), photogrammetry, 2d to 3d conversion, etc. Check the "3D Software" tab for my free 3d software. Turn photos into paintings like impasto oil paintings, cel shaded cartoons, or watercolors. Check the "Painting Software" tab for my image-based painting software. Problems running my software? Send me your input data and I will do it for you.
In this post, I am gonna revisit Depth Map Automatic Generator 3 (DMAG3) which is a depth map generator based on the "graph cuts" technique. The stereo pair I am gonna use comes from the 2014 Stereo Dataset that originates from Middlebury.
Left image.
Right image.
The original stereo pair is 2800 pixels wide, which is way too wide for DMAG3. I reduced the width to 700 pixels. I estimated the minimum disparity to be 10 and the maximum disparity to be 80. It doesn't have to be exact. I used the 64 bit version of DMAG3 available at 3D Software.
Depth map obtained using window radius = 2, gamma proximity = 17, gamma color similarity = 14, lambda = 10, and K = 30.
Corresponding occlusion map.
These are the default parameters (as of today). Here, I want to increase the window radius to get better accuracy. On my machine, this caused DMAG3 to crash because it ran out of memory. I therefore switched to the 64 bit version. By the way, the occlusion map looks ok, therefore I won't have to play with parameter K.
Depth map obtained using window radius = 8, gamma proximity = 17, gamma color similarity = 14, lambda = 10, and K = 30.
I want to go back to the previous parameters and reduce the smoothness by lowering parameter lambda.
Depth map obtained using window radius = 2, gamma proximity = 17, gamma color similarity = 14, lambda = 5, and K = 30.
Finally, I am gonna increase the window radius (back to 8) keeping the lambda at 5.
Depth map obtained using window radius = 8, gamma proximity = 17, gamma color similarity = 14, lambda = 5, and K = 30.
I am gonna stop right here fiddling around with the parameters, as I don't think the depth map can be improved much (automatically). It does not hurt to smooth this last depth map with Edge Preserving Smoothing 5 (EPS5).
Depth map after edge preserving smoothing. Now, we are ready for the best part: generating an animated gif.
This is the wigglegram aka animated gif obtained by uploading the left image and the depth map (make sure you invert the colors prior) to depthy (a very excellent web site). Depthy even allows you to use a brush to fix up the depth map while checking the animation (a truly wonderful tool).
There appears to be a new Middlebury stereo dataset: 2014 Stereo datasets. The motorcycle below is one of the stereo pairs on offer.
Left view of motorcycle. This image is 1200 pixels wide. The original stereo pair is much larger. When doing stereo matching, I always try to limit the largest dimension to be around 1200 pixels.
Depth map and occlusion map for min disparity = 0, max disparity = 100, window radius = 12, alpha = 0.9, truncation value (color) = 7, truncation value (gradient) = 2, epsilon = 4, number of smoothing iterations = 1, and disparity tolerance (occlusion detection) = 0.
It's actually a pretty decent depth map but it doesn't hurt to fiddle around with the parameters and see if things can be improved. It's not always easy to tell whether one depth map is better than an other (often, you really have to render the 3d scene to really tell) and there is a lot of trial and error involved. Let's see if we can get a better depth map by solely relying on color for stereo matching, which is done by setting alpha to 0.
Depth map and occlusion map for min disparity = 0, max disparity = 100, window radius = 12, alpha = 0.0, truncation value (color) = 128, truncation value (gradient) = 2, epsilon = 4, number of smoothing iterations = 1, and disparity tolerance (occlusion detection) = 0.
Ok, not a good idea. Maybe, decreasing the truncation value (color) would help, although I haven't tried. Let's go back to the previous parameters and increase the window radius.
Depth map and occlusion map for min disparity = 0, max disparity = 100, window radius = 24, alpha = 0.9, truncation value (color) = 7, truncation value (gradient) = 2, epsilon = 4, number of smoothing iterations = 1, and disparity tolerance (occlusion detection) = 0.
Again, not a tremendous idea. Let's increase the disparity tolerance so that we get fewer occlusions.
Depth map and occlusion map for min disparity = 0, max disparity = 100, window radius = 12, alpha = 0.9, truncation value (color) = 7, truncation value (gradient) = 2, epsilon = 4, number of smoothing iterations = 1, and disparity tolerance (occlusion detection) = 4.
I think we can increase the disparity tolerance some more and see what happens.
Depth map and occlusion map for min disparity = 0, max disparity = 100, window radius = 12, alpha = 0.9, truncation value (color) = 7, truncation value (gradient) = 2, epsilon = 4, number of smoothing iterations = 1, and disparity tolerance (occlusion detection) = 8.
It's probably worth a try to decrease the window radius.
Depth map and occlusion map for min disparity = 0, max disparity = 100, window radius = 6, alpha = 0.9, truncation value (color) = 7, truncation value (gradient) = 2, epsilon = 4, number of smoothing iterations = 1, and disparity tolerance (occlusion detection) = 8.
Ok, let's settle on that depth map even if it's not the best one, because one could spend a lot of time playing around parameters with not much of a payoff guarantee.
This is what you can see when you load the left image and the depth map into Gimpel3d. The depth map is obviously not perfect. The spikes could be probably be ironed out by applying a little dose of Edge Preserving Smoothing (EPS5) and the areas that are clearly wrong could be painted over in Photoshop or Gimp with your favorite brush. Of course, the "things" that connect objects at different depth are a bit of an eye sore but they cannot be helped, I am afraid. These are the areas that get uncovered when you don't look at the scene straight on.
This the animation gif created by DEPTHY using the depth map we created last (make sure you invert the depth map color because depthy.me expects black to represent the foreground, not white). If you're not too picky, it looks ok. Actually, more than ok. Even though the scene in Gimpel3d showed quite a few problems, the animation gif is rather pleasant to look at (and get hypnotized by). It goes to show that you don't have to have perfect depth maps to get a smooth and relatively accurate 3d wiggle. Now, to get a fully rendered 3d scene, that's a whole different story as you can see in the Gimpel3d video above. In my opinion, one would probably need to cut up the image (and depth map) in layers (one layer per object in the image as well as the corresponding layer in the depth map). Kinda like what you do in a 2d to 3d conversion. So, in our case, maybe one pair of layers for the bike and another pair for the background. You certainly also might want to do some in-painting to extend the background objects, just like for a 2d to 3d conversion. I have never tried to load multiple images and multiple depth maps into Blender but I think it should be doable and not too painful. Maybe I'll do that in an upcoming post, who knows?
Just for fun, let's see what Depth Map Automatic Generator 3 (DMAG3) does with the same stereo pair as input. Recall that DMAG3 is a "graph cuts" stereo matching algorithm, which means it's gonna be (much) slower than DMAG5.
Depth map obtained with DMAG3 using window radius = 2, gamma proximity = 17, gamma color similarity = 14, lambda = 10, and K = 30.
The video below shows how to load a 2d image and a depth map to render a 3d scene in Blender using the "Displace" modifier. A Blender expert I am not, so if there's a better way to do this, let me know! The black areas in the depth map correspond to pixels for which the depth is not known. Remember that the darker the grayscale value is, the further away the pixel is.
Steps:
1) Load the depth map using "import images as planes".
2) Subdivide the mesh (in edit mode). The more you subdivide, the better the scene is gonna be but obviously, the slower things will become.
3) Create a "Displace" modifier using the texture from the depth map. Make sure the "Texture Coordinates" is set to "UV".
4) Create a new material and texture (use the 2d image as the texture).
5) Disable the depth map texture.
6) Switch to "UV Editing" screen (go into "Edit Mode") and use the 2d image for the mapping (instead of the depth map).
7) Apply the "Displace" modifier so that the mesh is actually modified according to the depth map.
I think that you can skip the creation of a new material and texture, go into "UV Editing", and just replace the depth map with the 2d image.
What's cool is that after you have applied the "Displace" modifier, the mesh that started as planar has now moved according to the depth map. Of course, that mesh is fully editable and the 3d scene can be adjusted rather easily (I think) if the depth map was not super accurate to begin with. Note that even if the depth map is perfect, you still have to come up with a plan for the areas that become visible when the camera moves around. These areas correspond to those elongated faces that bridge the gap between objects at different depths. I guess one could delete those faces and fix up the mesh so that you don't get holes when you move around with the camera, but that's quite a bit of work. Another approach would be to load one depth map per object, that way, at least, you don't get the elongated faces that connect the objects. Of course, this would involve cutting up the 2d image (and the corresponding depth map) in Photoshop or Gimp but I think this could be a good solution. I'd be interested to know if you, dear reader, have an idea on how to do all this efficiently.
Now that I think about it, I think one could probably load the 2d image (as a plane), create a new material and texture for the depth map (disabling it right away), and apply the "Displace" modifier to the depth map. But, as usual with Blender, why do simple when you can do (much more) complicated. Well, I tried to do it that way but it doesn't seem to work. I am probably doing something wrong. Many times, the difference between success and failure in Blender is one wrong mouse click in some obscure checkbox.
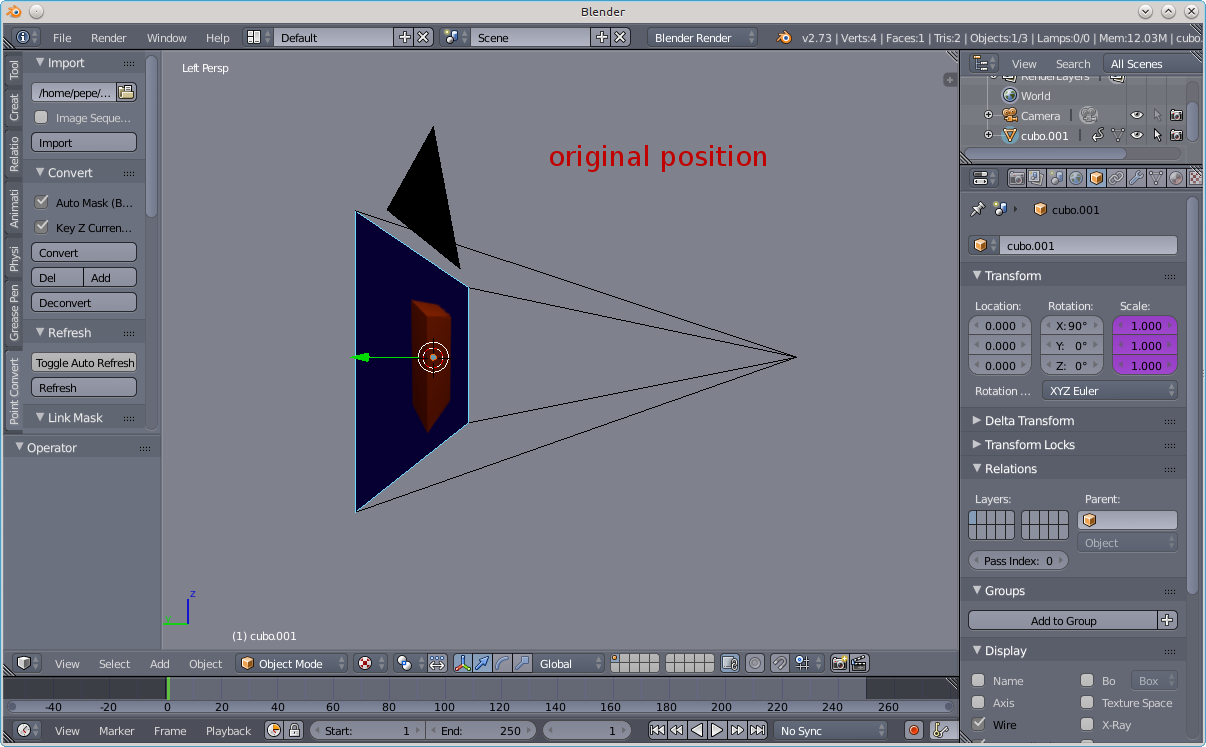
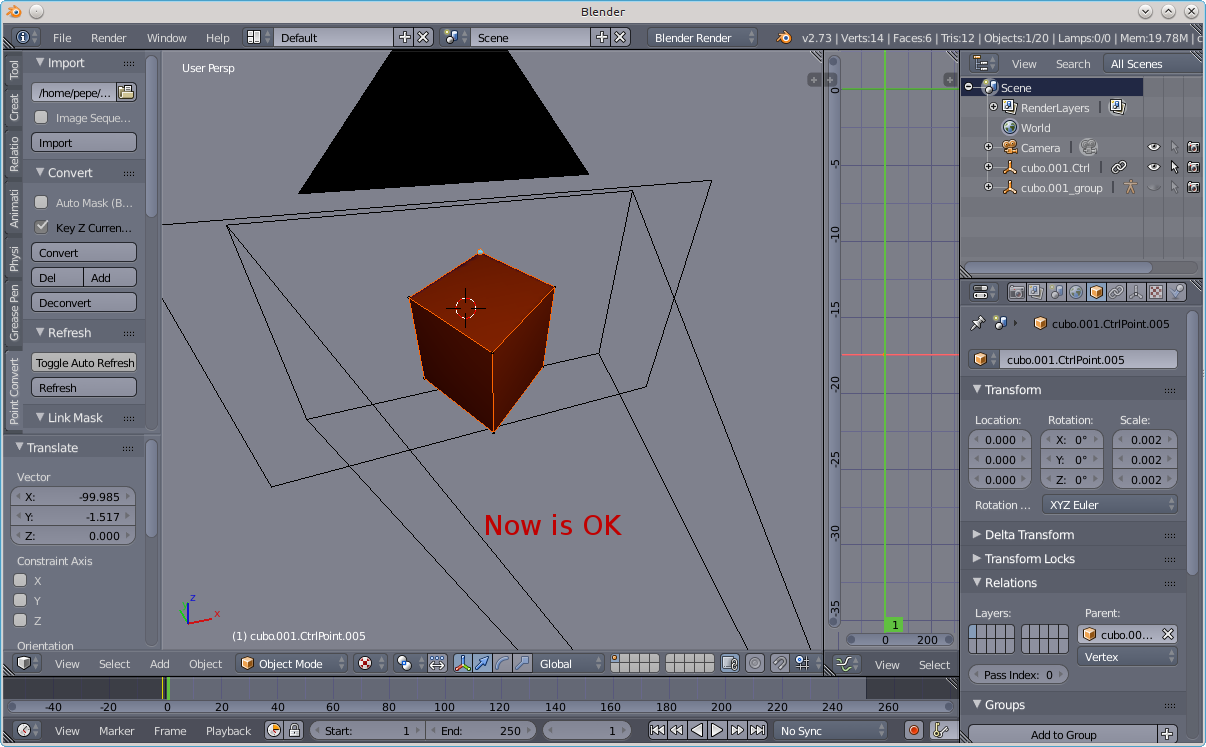
The following attempt at a 2d to 3d conversion is to showcase the Blender PointConvert3D add-on available at Point Convert 3d for exactly 0 dollar. I got wind of this add-on to Blender via my amigo from Sevilla, Pepe.
With PointConvert3d, you basically load the pieces of the 3d scene as image planes, the nice part being that you don't have to worry too much about maintaining proper perspective because the add-on does it for you. When you move (along the Y axis) a piece of the scene, it is scaled automatically, and when you view the scene head-on, you always see the original 2d image. Every time you load a piece of the scene, you mesh the corresponding object as cleverly as possible and then go to work by moving (along the Y axis) selected vertices. The moving is done via a graph editor.
This is the 2d image we are gonna start with. Using Gimp, I extracted the body, spout, and handle of the coffee pot, as well as the background as png files (to preserve transparency).
This is the body of the coffee pot.
This is the spout of the coffee pot.
This is the handle of the coffee pot.
This is the background. I have to admit I was a bit lazy on this one but it doesn't really matter as long as the camera doesn't move too much when you animate the 3d scene.
This is the rendered 3d scene. It could be much better but you get the idea.
This is a tutorial on how to use PointConvert3D.
If you are not happy with the mesh after a "convert" (the deformed object doesn't look right no matter how you move the vertices), you need to "Deconvert" it (select the "convert" item in the "group" in the Outliner area), modify the mesh, and then "Convert" it again.
PointConvert3d is pretty cool but it's still not an easy process (depends on the 2d image you start with). Those 3d conversions are neat and all, but unless I get paid royally, I don't think I gonna make too many of those.
Here's a series of slides that explain the whole process of 2d to 3d conversion using PointConvert3D in Blender (courtesy of Pepe from Sevilla):








.gif)